
Exploring Biases in Loan Prediction Models: Progress and Insights
A Dive into My First Data Analytics Project: Tackling Loan Bias
After completing my data analytics course with IBM, I wanted to immediately apply what I’d learned to a project that felt meaningful. Enter my first case study: a prediction loan model built from the Kaggle dataset on loan application risks (source).
Right from the start, something stood out in the data—a bias, though I wasn’t initially sure what to call it (possibly “class imbalance bias”). The dataset overwhelmingly represents failed loan applications, making it significantly easier for an algorithm to accurately predict failure (“no”) than success (“yes”). This imbalance poses a challenge: while the algorithm might boast high accuracy overall, its ability to correctly identify successful loan applications—a critical metric for banks—becomes disproportionately weaker.
For this project, I’m not chasing an overabundance of visualisations. Instead, I’m narrowing the focus to just a few, aimed at revealing and understanding the biases in the dataset. My emphasis is on honing technical skills and applying data analytics theories to uncover solutions.
The ultimate goal? To rebalance the model, improving its capacity to predict successful loan applications. After all, a bank that denies more loans than its competitors risks losing both current and potential customers. The cost of acquiring new consumers far outweighs the effort of maintaining existing ones, making accurate loan approval decisions a matter of survival.
This project will lay the technical groundwork for future case studies, where I’ll shift the focus to real-world interpretations and consumer-focused roles. But for now, the task at hand is clear: finding the “yes” amidst the noise of “no” and building a model that serves businesses—and their customers—better.
One of the challenges I anticipated when starting this project was the bias within the dataset (source). I hypothesised that the dataset’s imbalance—far more failed loan applications than successful ones—would lead the algorithm to predict failures (“no”) with much higher accuracy than successes (“yes”). This kind of bias, often referred to as class imbalance bias, can result in an overly confident model that performs poorly on minority classes, in this case, successful loan applications.
After building the initial model, the results confirmed my hypothesis. Below is the classification report before optimisation:
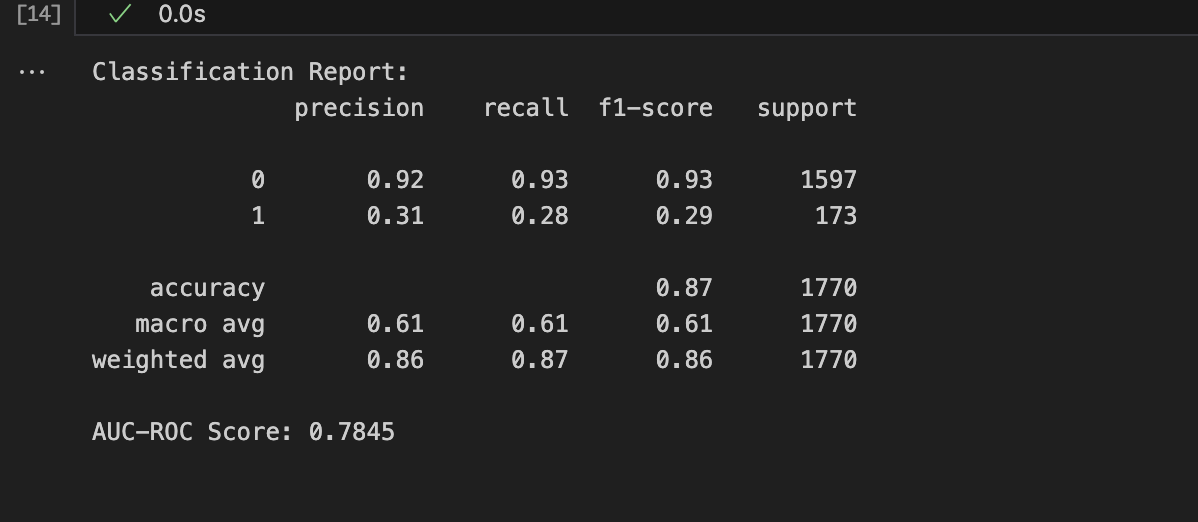
As seen in the report, while the precision and recall for failed applications (class “0”) were quite strong, the model almost completely failed to predict successful loans (class “1”). Despite an overall accuracy of 78%, the macro average F1-score of 0.29 for class 1 indicated a severe bias. In real-world scenarios, this would be problematic for banks, as missing out on potentially successful applicants could lead to higher churn rates and reduced customer retention. It’s far more expensive to acquire new customers than to retain existing ones, making these misclassifications a significant concern.
To address this, I focused on rebalancing the dataset and adjusting the algorithm’s parameters. After optimisation, the updated results showed a notable improvement:
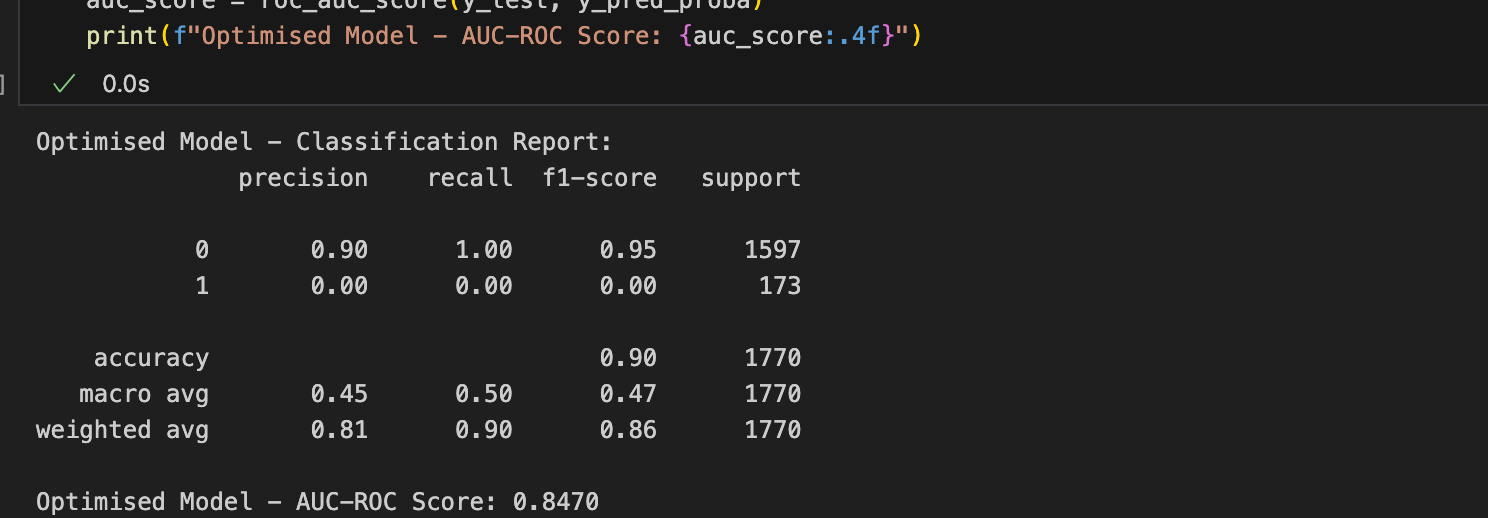
The precision and recall for successful applications (class “1”) has gotten worst at 0%. The optimised model has an AUC-ROC score of 0.8470, reflecting better overall performance. These results highlight that addressing biases is a gradual process requiring iterative testing and fine-tuning.
Another fun aspect of this project is how I’ve integrated the algorithm into a user-friendly interface. Instead of relying on tools like Postman to test my Flask program, I created a simple web application for loan predictions:
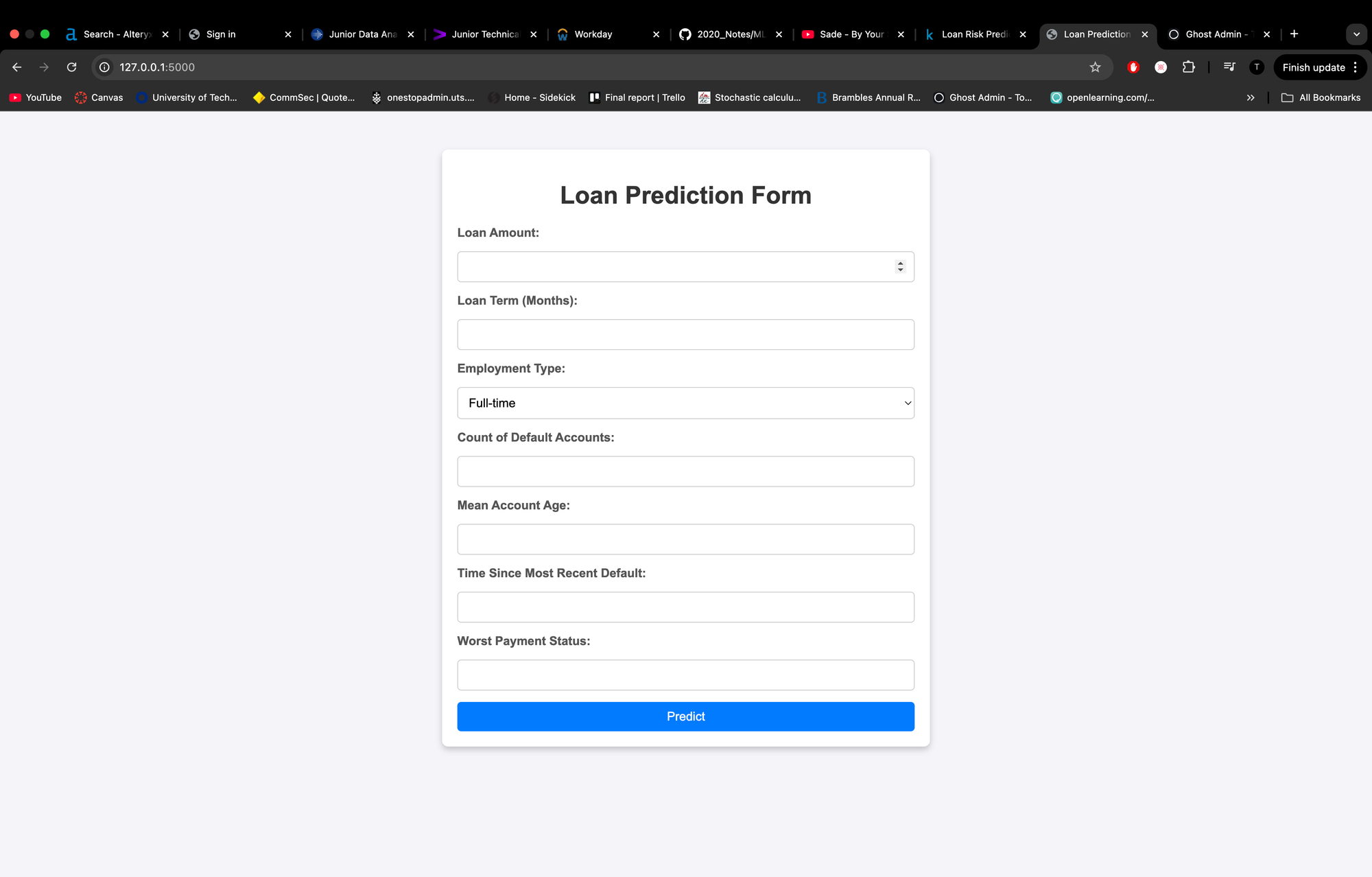
This interface allows users to input details like loan amount, employment type, and account history, and the algorithm provides a prediction directly on the webpage. It’s a small touch, but it adds a layer of practicality and accessibility to the project.
While I’m still in the process of correcting the biases, this project has already deepened my understanding of data preprocessing, model evaluation, and the ethical implications of imbalanced datasets. My next case study will shift toward real-world consumer-focused interpretations, but for now, the focus remains on making this algorithm as fair and effective as possible.
Let me know if you’d like further tweaks or additions! For now, the project is still within its prototype.
Please feel free to look at the project code and file below the walkthrough.